AI Journal Analyzer
Annual Spotify Wrapped, But For Journaling (Fall 2024 - Ongoing)
1/31/20253 min read
The Challenge
Problem Discovery: As an avid journaler for 6+ years, I analyzed my habits and spoke with other journalers on reddit.com/r/Journaling (2.1M subs). I identified 3 core user needs for avid journalers:
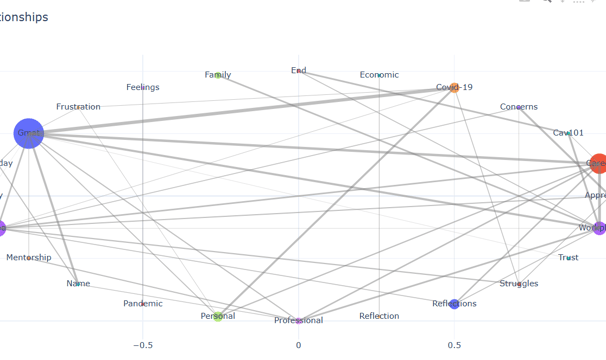
Discovering emotional patterns over time
Identifying recurring topics and their impacts over time
Gaining objective insights that might not be apparent through manual review
Feature Prioritization: I prioritized features based on three criteria:
Impact on core user insights
My technical abilities and feasibility within cost constraints
Development time
Results: Successfully built an MVP for an AI-powered journal analysis tool that identified emotional patterns and key insights from years of personal journal data.


Project Summary

Core Tools Used:
AI/ML: V0, Replit, Cursor, Gemini, OpenAI API (GPT-4o-mini, Embeddings), RAG, NumPy, Pandas, Matplotlib
Languages: Python, NextJS, HTML, JSON, React,
Databases: PostgreSQL with pgvector, SQLAlchemy, Psycopg2, LangChain
Core Skills Learned:
API Integration, AI Implementation, Prompt Engineering, Product Strategy, Databases, Coding Using AI, Developing an MVP
Timeline:
V1 (MVP): Fall 2024
V2: Winter 2024 - Ongoing
Architecture:
Raw Journal Entry → Preprocessing → Embedding Generation → Sentiment Analysis → Pattern Detection → Multi-modal Output
Processed 2.1K journal entries (375K words) spanning 6 years
Approach


Development Process
V1: MVP and Proof of Concept
The initial version focused on validating the core concept with minimal complexity:
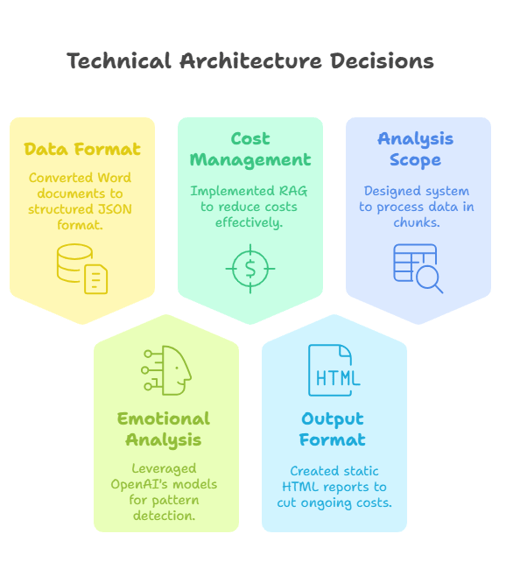
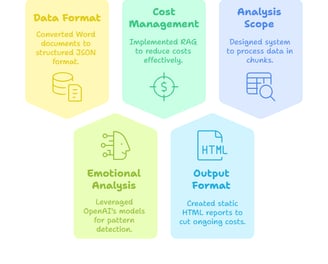
Data Ingestion: Built a converter to transform personal journal entries into structured JSON format
Embedding Generation: Created embeddings for each journal entry to enable semantic analysis
Pattern Detection: Implemented two approaches for comparison:
Clustering-based approach using HDBSCAN (computationally efficient but less accurate)
LLM-based analysis using GPT-4o-mini (more accurate but higher cost)
Visualization: Generated static HTML reports with emotional timelines and pattern descriptions
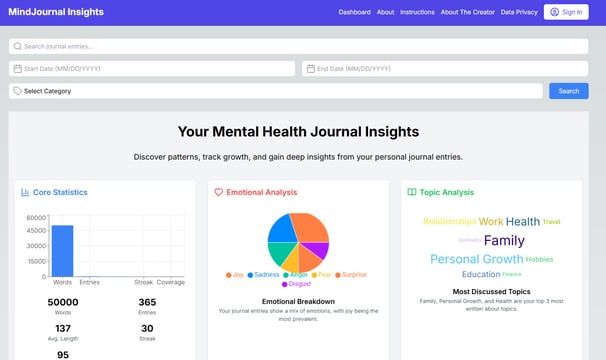
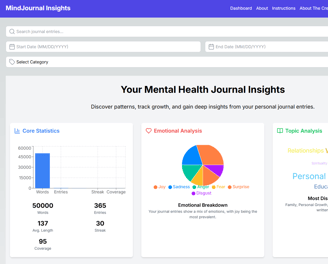
V2 (Ongoing): Scalable Web Application
Based on learnings from V1, I designed a more robust solution:
Web Application: NextJS frontend with interactive D3.js visualizations
Backend Processing: Python with FastAPI deployed on Replit, connected to Cursor via SSH for easier AI coding
Enhanced Analysis: Two-phase processing approach:
Initial comprehensive analysis (one-time processing)
Search infrastructure for AI-powered features
Data Storage: PostgreSQL with pgvector for efficient embedding storage and retrieval
Advanced Features: Topic discovery, writing style analysis, image analysis, other data sources (i.e. spotify wrapped data, health data, etc) and personal growth tracking
Key Technical Challenges & Solutions
Challenge 1: Context Length Limitations
With 375K words (~500K tokens), processing the entire journal history exceeded API context limits.
Solution: Implemented month-by-month processing with aggregation of results, allowing for scalable analysis without sacrificing contextual understanding.
Challenge 2: API Cost Management
Full processing of all journal entries would incur significant API costs.
Solution: Leveraged embeddings and RAG to reduce token usage, processed data in batches, and implemented caching to prevent redundant API calls.
Identifying emotional patterns across time required sophisticated analysis beyond simple sentiment scoring.
Solution: Combined embedding-based similarity measures with GPT-4o-mini's natural language understanding to detect nuanced patterns in emotional expression.
Challenge 3: Complex Pattern Detection
Product Insights
User-Centered Design: Starting with a personal need led to more intuitive feature prioritization
Technical Trade-offs: Making deliberate choices between ideal and practical implementations (JSON vs. Database, static vs. hosted)
Incremental Development: The two-version approach allowed for validating core concepts before adding complexity
Technical Learnings
AI Integration: Gained practical experience integrating OpenAI's API, managing tokens, and optimizing costs. Learned how to code using AI tools like Claude, Cursor, Replit, and V0.
RAG Implementation: Developed understanding of retrieval augmented generation for enhancing LLM outputs
Embeddings Usage: Learned to effectively utilize embeddings for semantic analysis and pattern detection
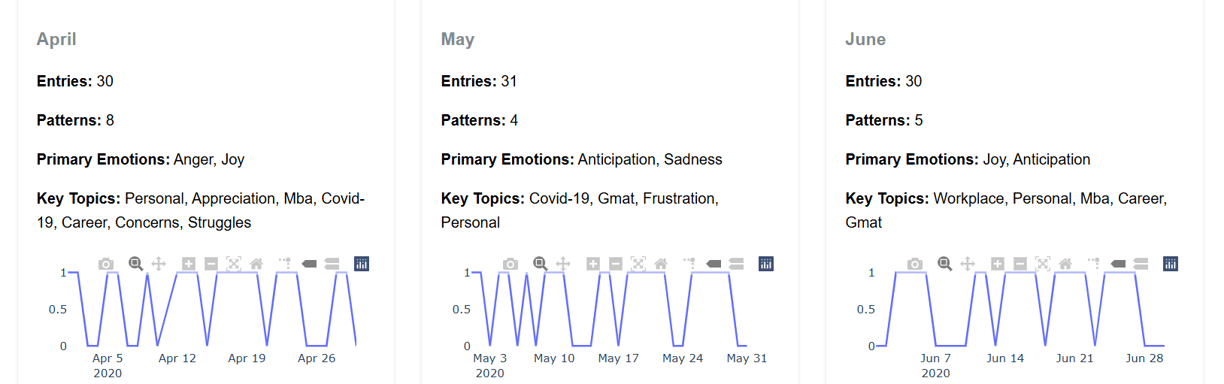
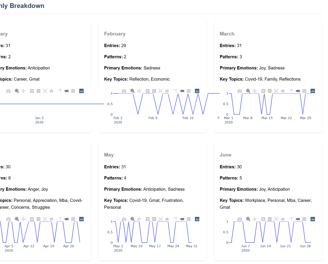
Next Steps (V2 - Ongoing)
Multi-Format Support: Add support for handwritten journals through image-to-text transcription
Enhanced Visualization: Implement more interactive visualization options similar to Spotify Wrapped
Comparative Analytics: Develop year-over-year comparison features to track personal growth
Community Version: Create a privacy-preserving version that can be used by the journaling community
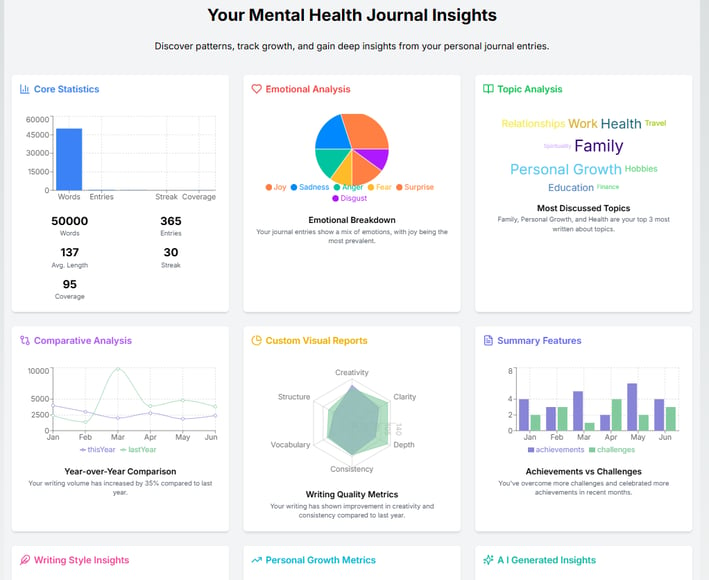
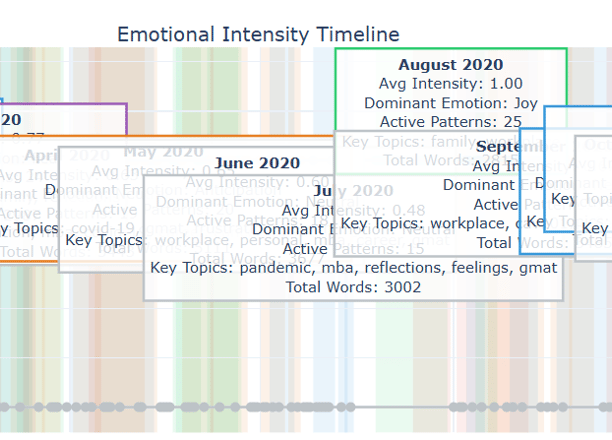
Image shown is a mockup using V0.dev. V2 of the AI journal analyzer is still in development.